dataMinds News Round up –
April 2023
Azure
Welcome to the Azure Synapse Analytics March 2023 update! This month, we have the General Availability of Multi-Column Distribution and Prive Endpoint support for Cosmos DB to Azure Data Explorer Synapse Link. We also have additional updates in SQL, Apache Spark for Synapse, and Synapse Data Explorer! Read about all of these new features below! Ryan Majidimehr walks you through Azure’s newest releases!
In this article, Nick Salch will discuss how to configure alerts for you Azure Synapse dedicated SQL pool and provide recommended alerts to get you started. Enabling alerts allows you to detect workload issues sooner allowing you to take action earlier to minimize end-user impact.
In Azure Synapse, alerts can be triggered by Azure Metrics data or data in Log Analytics, this post will provide examples for both scenarios.
Synapse Dedicated pools have been battle tested at enterprise customers across the globe. We deal with data in the magnitude of PetaBytes. Synapse can provide you with the scale of the cloud and the high performance required for your enterprise-grade requirements.
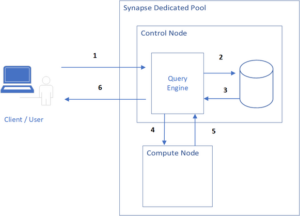
From a performance point of view, it’s important to understand where the bottlenecks are. Sarath Sasidharan focuses on the different steps a query goes through; from the time the query is fired from the client until it returns back. Delay caused in any of the steps would impact the overall run-time of the query and hence indicate degraded performance.
SQLBits 2023 was an unforgettable event that brought together Microsoft SQL Server enthusiasts from all over the world for an epic week of learning and connecting.
This year the conference took place at the International Convention Centre in Newport, Wales, from March 14 through 18, with 300+ sessions over the course of five days.
Missed out? Barry Smart got you covered with the best bits of SQLBits 2023!



SQL
Today, Apache Spark has become a dominant player in the big data processing area. A common design pattern is to copy raw data to the bronze quality zone. Then various notebooks enrich and/or transform the data between the silver and gold quality zones. At the end of processing, data is consumed from the lake for reporting and/or analytics. Due to the large number of database management systems, reading from (pull to bronze) and writing to (push from gold) a database is common. Since many libraries work at a dataframe (table) level, the developer might have to write a stored procedure to MERGE a staging table with an active table.
How can we perform data processing using Apache Spark for SQL Server? John Miner shines his light.
Power BI
If you missed out on the big announcement last week about Tabular Model Definition Language and the future of Power BI version control at SQLBits last week, then the recording of the session has already been published. If you’re a professional Power BI developer you must watch this one! Mathias Thierbach guides you through the future of version control for tabular models.
Power BI includes capabilities to enable users to understand the content they own, and how different items relate to each other. Sometimes you may need a custom “big picture” view that built-in features don’t deliver, and this is where the Scanner API comes in. Matthew Roche did the writing.
Want a dev and production environment in Power BI but don’t have Power BI Premium? Patrick shows you a way to switch a report from Dev to Production without Premium or without APIs.



