dataMinds News Round up –
December 2023
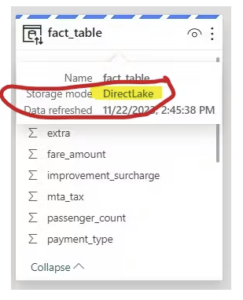
Direct Lake datasets are a special type of tabular datasets that are directly linked to the Fabric Lakehouse. This means that whenever the data in the Fabric Lakehouse changes, the Direct Lake dataset reflects those changes automatically, without any additional processing or refresh.
This means that the consumers of reports based on a Direct Lake dataset can see the latest data as soon as the Lakehouse changes. Thus, also eliminating the final step in a potential lengthy ETL process.
In this post, will demonstrate how you can use Tabular Editor 3 to create a new Direct Lake dataset from scratch and configure it in a few simple steps.
In the flurry of announcements at MS Ignite last month, one significant feature related to Direct Lake got buried. You can now control the fallback behavior of the Direct Lake semantic model. Sandeep Pawar explains what this fallback is all about, walks through 4 different methods to control this behaviour and shows you how to verify which mode queries are being evaluated in.
Power BI and Microsoft Fabric use Azure DevOps as the core component for their version and source control. The integration with Azure DevOps and Git helps maintain a copy of the source code and version it. It allows access to it anytime needed, plus the multi-development aspect added. In this article and video, Reza Rad will learn how this integration works.
Learning Azure SQL and getting a certification requires reading many books and articles. For newbies and professionals, sometimes finding the right materials isn’t straightforward. In this article, Daniel Calbimonte looks at several resources that can help you prepare for Microsoft Exam DP-300.
With the rise of OpenAI’s ChatGPT, millions have become familiar with the power of Generative AI and other Large Language Models (LLMs). The functionality of these models is also exposed by a set of APIs. This enables developers to create various solutions, including chatbots and business workflows that leverage LLMs. Bennie Haelen dives into the OpenAI API: setting up a development environment, creating an OpenAI account, and generating an API key.
In the realm of data science and analytics, extracting insights from data often involves a series of steps, typically conducted in Python using libraries like pandas. While powerful, pandas may face performance issues with large datasets and resource-intensive operations.
Aiming for a balance between robust functionality and efficiency, DuckDB emerges as an excellent alternative. As a high-speed, user-friendly analytics database, DuckDB is transforming data processing in Python and R.
Kurtis Pykes will explore:
- DuckDB’s unique features and capabilities
- Advantages of DuckDB over traditional data manipulation tools
- Practical use cases demonstrating DuckDB’s potential
- Guidelines for working with DuckDB in Python and R