dataMinds News Round up –
February 2023
Azure
“Should I use one data lake for all my data, or multiple lakes?”. Ideally, you would use just one data lake, but there are many valid use cases where customers could use multiple data lakes. James Serra to the rescue!
Ever wondered about the creation of a data sandbox to support customer engagement?
Paul Andrew gets you going by elaborating upon the what, why and how. Along the way, Paul also writes about the similarities in the creation of a sandbox compared to the ‘data product infrastructure as a service’ concepts included in a Data Mesh architecture.
Both Microsoft and OpenAI have announced they are extending on the 3 year partnership they already have to keep making advancements together around Artificial Intelligence (AI). This partnerships includes AI products like ChatGPT, DALL-E, GitHub Copilot, and the Azure OpenAI Service.
Typically you have a bunch of pipelines that are started by one or more triggers. Sometimes, a pipeline needs to be manually triggered. For example, when the finance department is closing the fiscal year, they probably want to run the ETL pipeline a couple of times on-demand, to make sure their latest changes are reflected in the reports. Since you don’t want them to contact you every time to start a pipeline, it might be an idea to give them permission to start the pipeline themselves. Koen Verbeeck walks the talk.
Microsoft Azure has several capabilities, including support for Machine Learning (ML) and Artificial Intelligence (AI). One of the AI and ML offerings that enable developers to build cognitive intelligence into applications is referred to as Azure Cognitive Services. This offering does not require direct Data Science or AI/ML skills and is low code/no code.
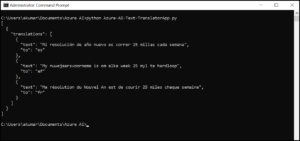
In this article, Ajay Kumar will provide an overview of Azure Cognitive Services’ Text Translation API, which is part of the Language category, and will elaborate on how to create a working Text Translation application.



SQL
Large databases usually have a negative impact on maintenance time, scalability and query performance. For maintenance, these large single databases have to be backed up daily while the amount of actual changing data might be small. For performance, tables without correct indexes result in full table or clustered index scans. As the data grows the total query time increase linearly. How can we decrease downtime for the maintenance window for large databases and optimize the performance of daily queries? John Miner shines his light.
Power BI
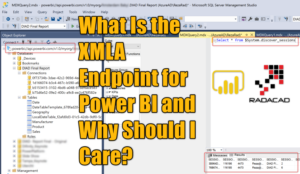
The XMLA endpoint term is still too technical for many Power BI report developers. Many people come to me asking what exactly is XMLA endpoint, and what are the benefits of it. What it can do? or most importantly; as a report developer, why should I care? Well, I will answer all of these questions in this article. Reza Rad digs into it.
You’ve set up Power BI Incremental Refresh and there is a day that is missed because schedule refresh failed or some other reason. What happens? Do you lose that data? Patrick did the testing for you!