dataMinds News Round up –
September 2023
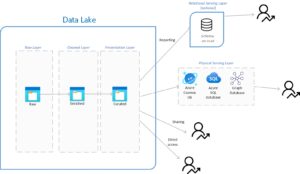
Data lakes typically have three layers: raw, cleaned, and presentation (also called bronze, silver, and gold if using the medallion architecture. Many times, companies will create a fourth layer outside of the data lake, called a relational serving layer. There is also another type of fourth layer, which can be called a physical serving layer. In this blog post James Serra will discuss the relational serving layer and the physical serving layer.
Ever wanted to normalize your data so it could be used in a Power BI report in a handful of minutes using GPT4’s code interpreter? Injae Park demonstrates how even best practices such as a star model are followed.
How does Azure Databricks work with Microsoft Fabric? With the recent announcement of Microsoft Fabric, this question might have appeared in your social media feed.
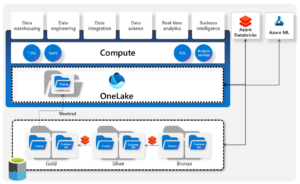
First, let’s quickly recap the basics of both products. Azure Databricks is a unified set of tools for deploying, sharing, and maintaining enterprise-grade data and AI solutions at scale. Azure Databricks today has widespread adoption from organizations of all sizes for use as a data processing and analytics engine as well as a data science platform. Microsoft Fabric is a unified analytics platform that brings together all the data and analytics tools that organizations need. Fabric brings together experiences such as Data Engineering, Data Factory, Data Science, Data Warehouse, Real-Time Analytics, and Power BI onto a shared SaaS foundation, all seamlessly integrated into a single service. Microsoft Fabric comes with OneLake, an open & governed, unified SaaS data lake that serves as a single place to store organizational data. In this article, Aaron Merrill outlines how Azure Databricks can work with OneLake to simplify organizations’ overall data journey.
Need to get the full overview of a Power BI and/or Fabric tenant? What are the users doing? What’s created? In this session, Just Blindbæk is giving the best of himself during a walkthrough of a complete monitoring solution to extract all the valuable tenant information including the activity events, the artifact metadata and the settings. You will learn how to setup and use Integration Pipelines in Azure Data Factory or Azure Synapse Analytics and get examples of querying the data with Azure Synapse Serverless SQL Pool. We will also discuss what questions you can get answered, when combining all the information. And then we will also cover alternative solutions.
Three types of objects in the Microsoft Fabric have similarities in what they can do for an analytics system. These three are; Lakehouse, Data Warehouse, and Power BI Datamart. All three objects provide storage for the data, which can be loaded into them using an ETL process and read using something like a Power BI report. In this article and video, Reza Rad will explain the actual differences and how to choose the best option for your implementation and architecture.
As you embark on an exciting chapter of your career, you’ll encounter various challenges and opportunities to enhance your SQL development skills. One tool that can revolutionize your workflow is GitHub Copilot. In this first of a blog of series, Subhojit Basak explores how GitHub Copilot can assist you in your SQL development tasks, providing intelligent code suggestions and speeding up your learning curve.
As Fabric buzz might have taken over your social walls, Anna Hoffman has you covered with an overview of the biggest announcements in Azure SQL during this year’s Microsoft Build.